
こんにちは!イノベーション本部の野村です。
今回はTensorflowの可視化ツールであるEmbedding projectorを使って
似た本どうしの距離を可視化してみたのでご紹介したいと思います。
Embedding projectorとは
Embedding projectorは、Googleの機械学習ライブラリであるTensorflowの
計算グラフや学習過程を可視化できるツールで、
高次元データを2Dもしくは3Dへ可視化することができます。
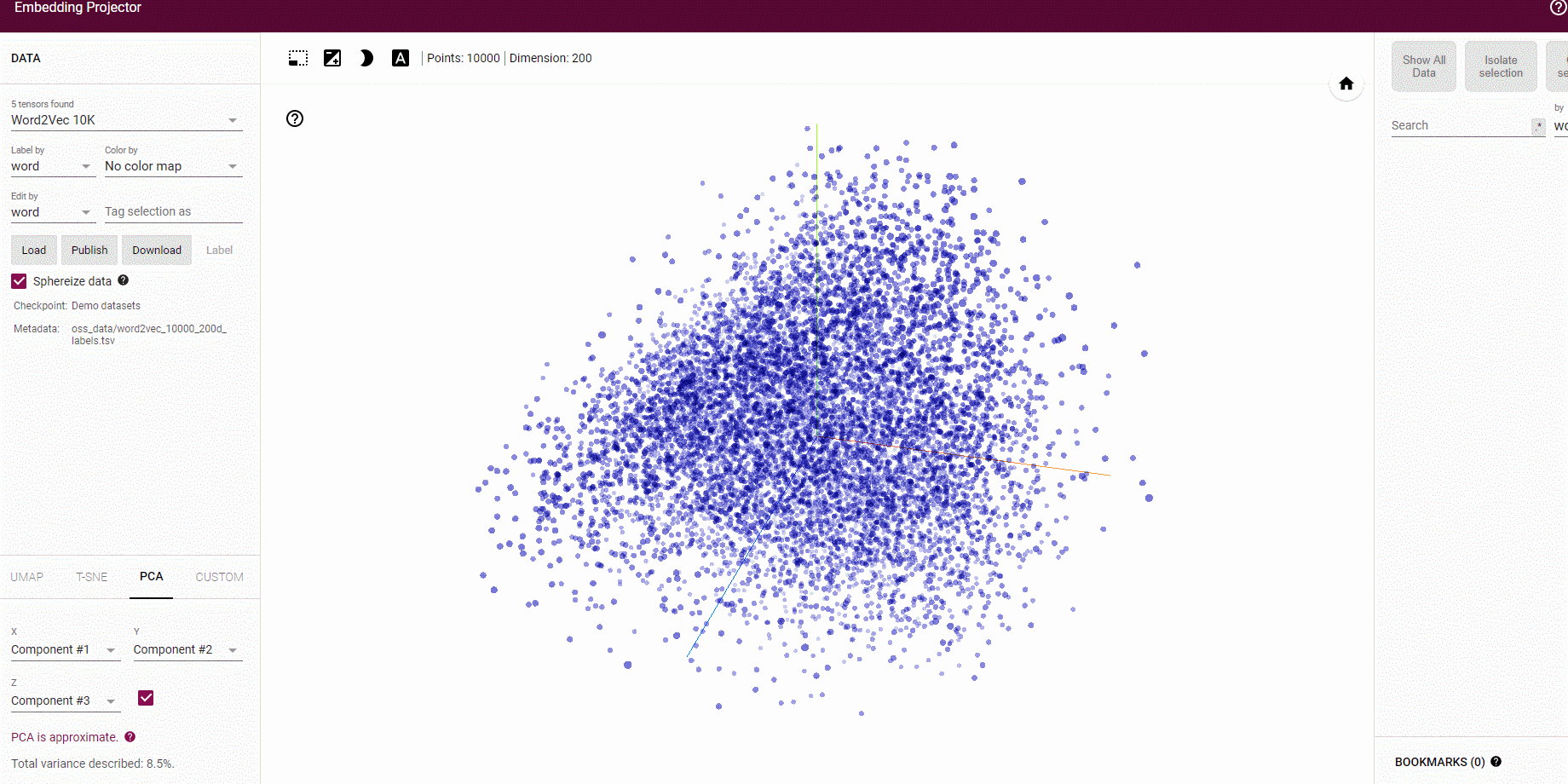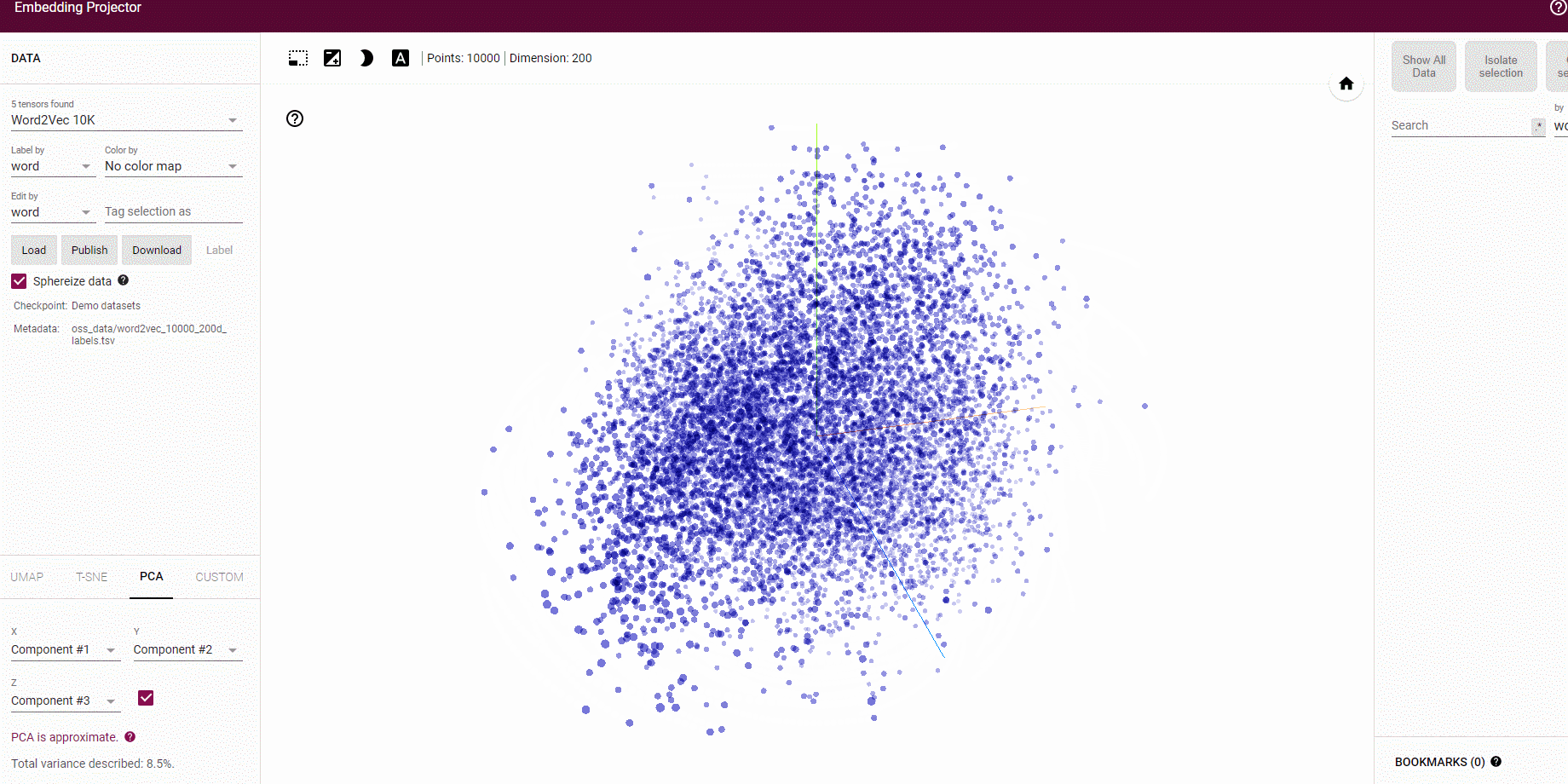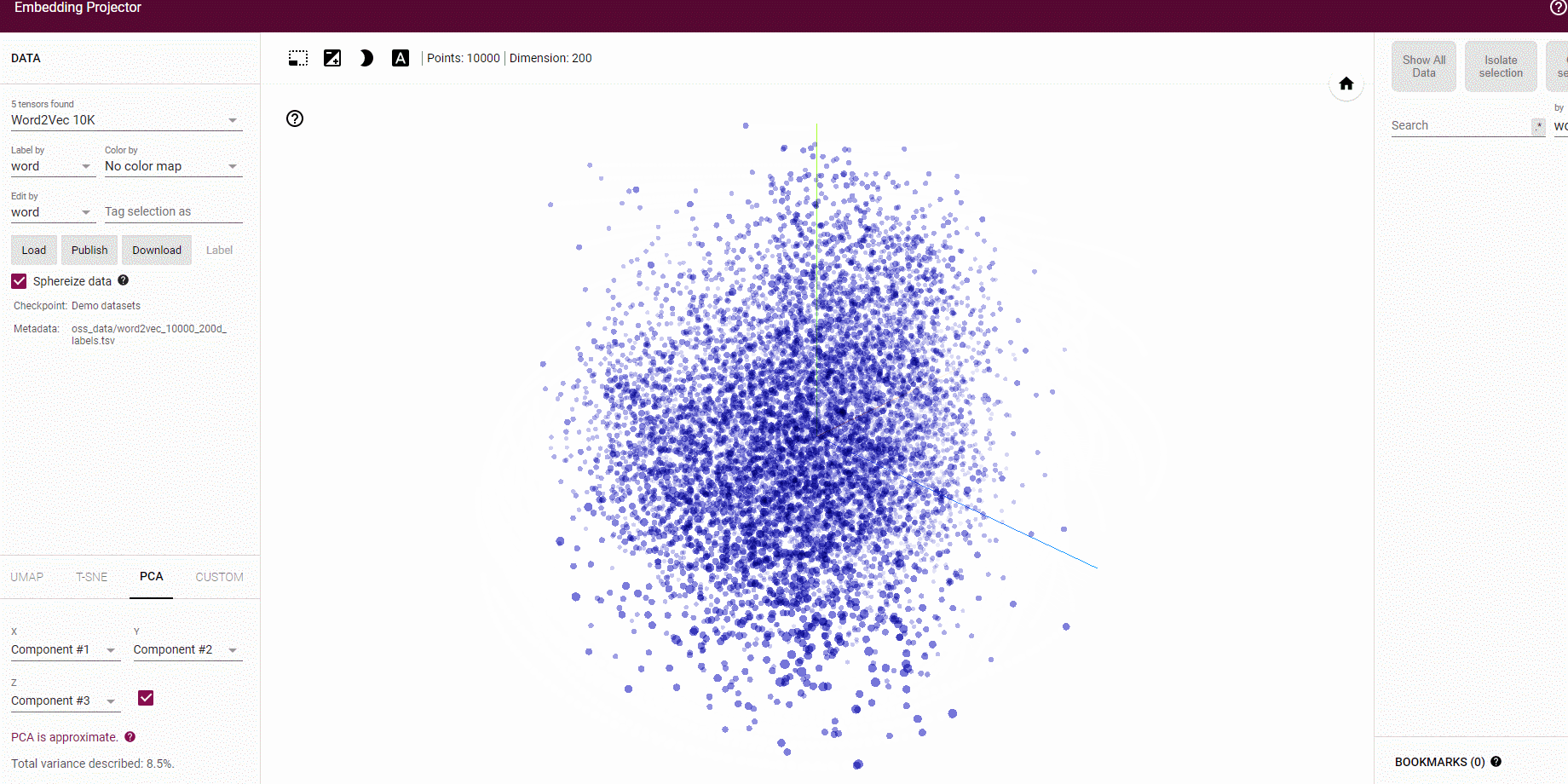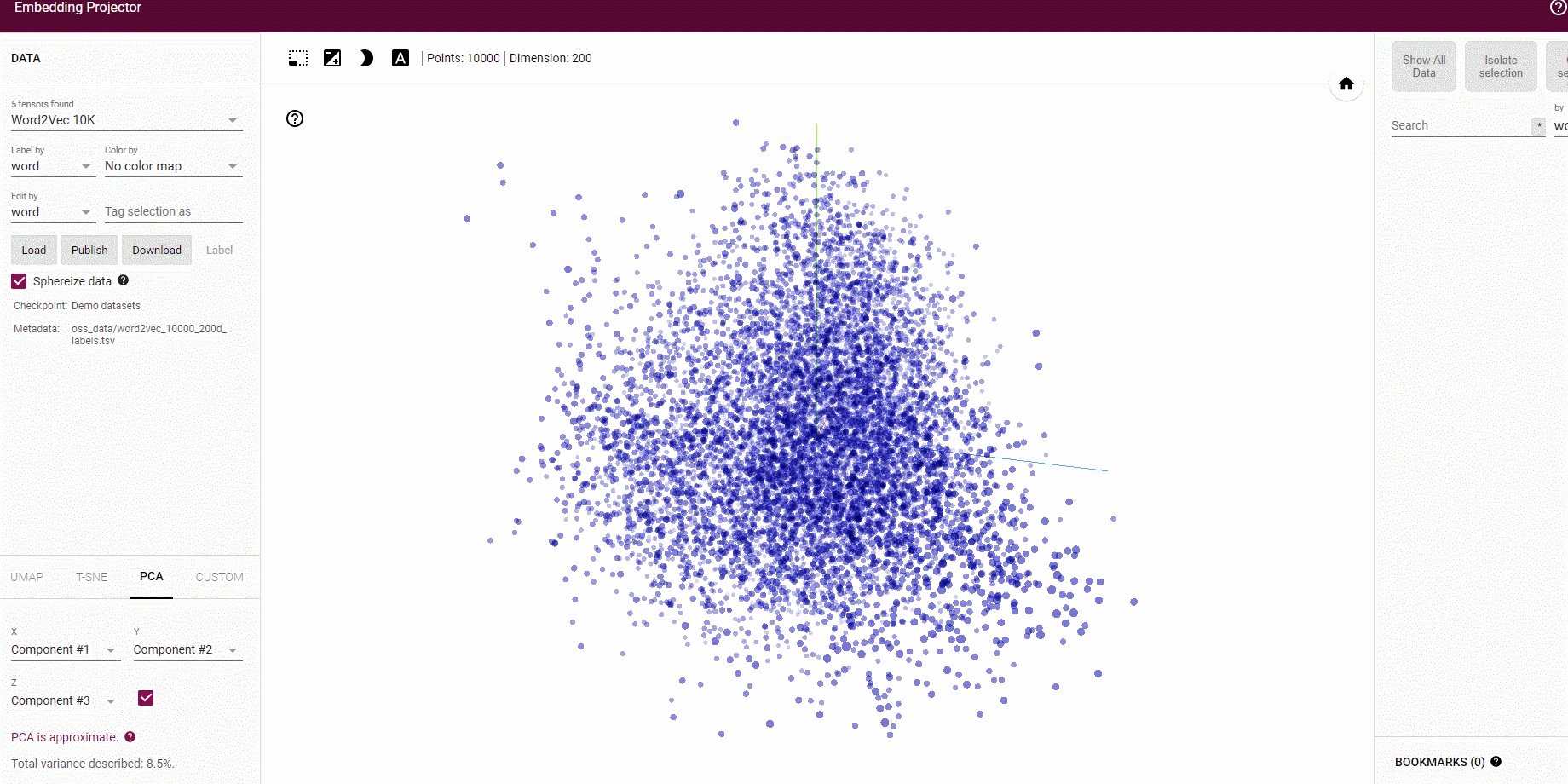
デフォルトでは主成分分析(PCA)による次元削減をすることで
word2vec等で学習した分散表現の埋め込みベクトルを可視化することが可能です。
やってみる
では早速やってみたいと思います。
データとしては、本の銘柄情報とその内容情報を3万件ほど学習させています。
また実施環境はGoogle Colabを利用しています。
0.準備
Googleドライブをマウントし、必要なツールのインストールとライブラリをimportしておきます。
(ランタイムのリセットが必要になります。)
!pip install tensorboard==1.14.0
!pip install tensorboardX
!pip install tb-nightly
from gensim.models.doc2vec import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
from tensorboardX import SummaryWriter
import gensim
import torch
import pandas as pd
import csv
1.内容情報の読み込み
まず、内容情報のデータをMecabを使って形態素解析し、csvへ出力しておきます。
(今回こちらの内容については割愛いたします。)
品詞は名詞、動詞、形容詞のみ取り出すようにし、基本形に直しておきました。
出力したcsvを読み込み、taggeddocumentを使って
trainingsにwordsとtagsをセットします。
f = open('/content/drive/My Drive/temp/mecab.csv', 'r')
trainings = [TaggedDocument(words = data.split()[1:],tags = [data[0:13]]) for i,data in enumerate(f)]
wordsには分かち書きされた内容情報、tagsにはISBNが入るようにしました。
2.Doc2Vecによる分散表現
Doc2Vecを使って、内容情報をベクトル化します。
今回、次元数は300、その他のパラメータは以下の感じにしました。
(学習にはGPUランタイムで3時間程かかりました。)
# トレーニング
m = Doc2Vec(documents= trainings, dm = 1, size=300, window=7, min_count=1, workers=4, epochs=1000)
こんな感じで内容情報がベクトル化されます。
m.docvecs.vectors_docs
3.Embedding Projectorで可視化
3万件全てを可視化してしまうと見づらくなるので、500件程度に絞り、
labelsにはベクトル毎に本のタイトル情報を入れておきます。
writer = SummaryWriter()
weights = m.docvecs.vectors_docs
weights = weights[:500]
labels = labels[:500]
writer.add_embedding(torch.FloatTensor(weights), metadata=labels)
以下のコマンドでGoogle ColabのセルにEmbedding Projectorが表示されます。
(もし、”No dashboards are active for the current data set.”と表示された場合は、
しばらくしてからTensorBoardのリロードボタンを押してみてください。)
%load_ext tensorboard
%tensorboard --logdir ./runs
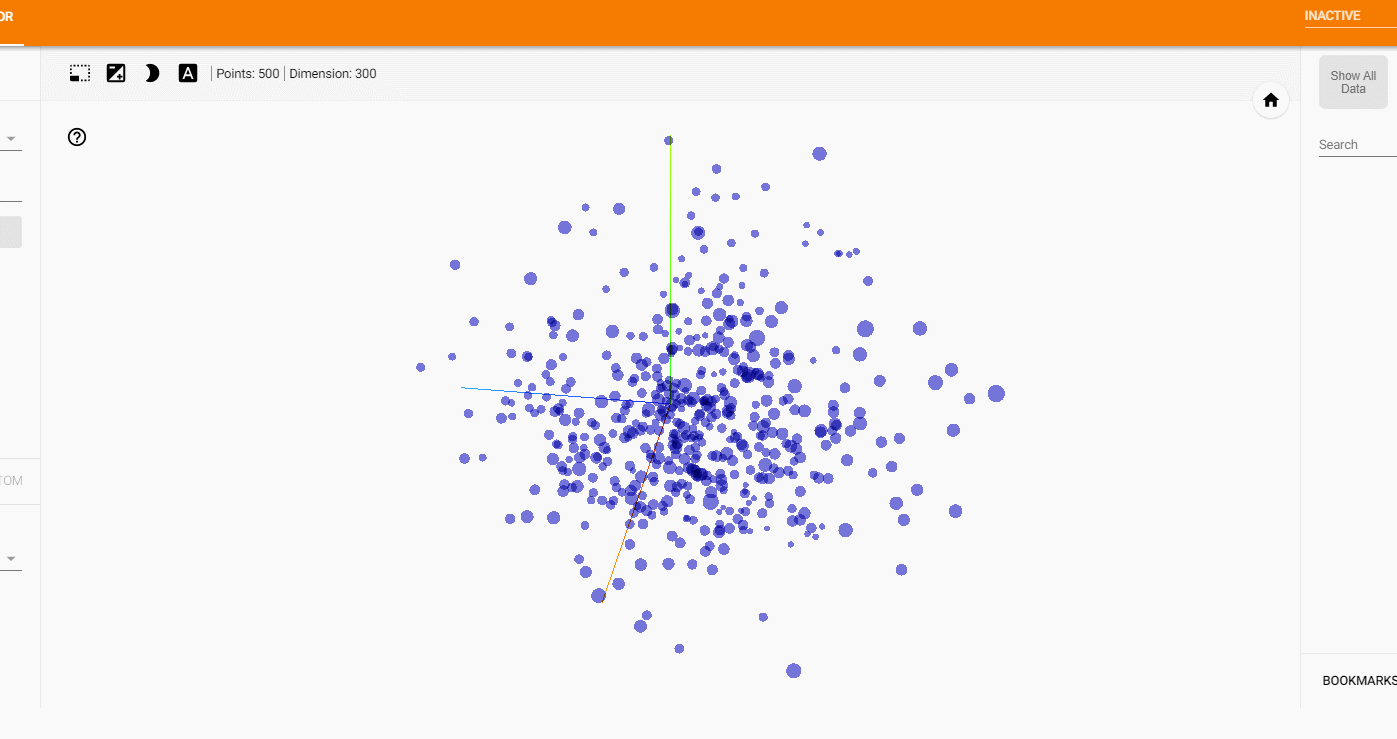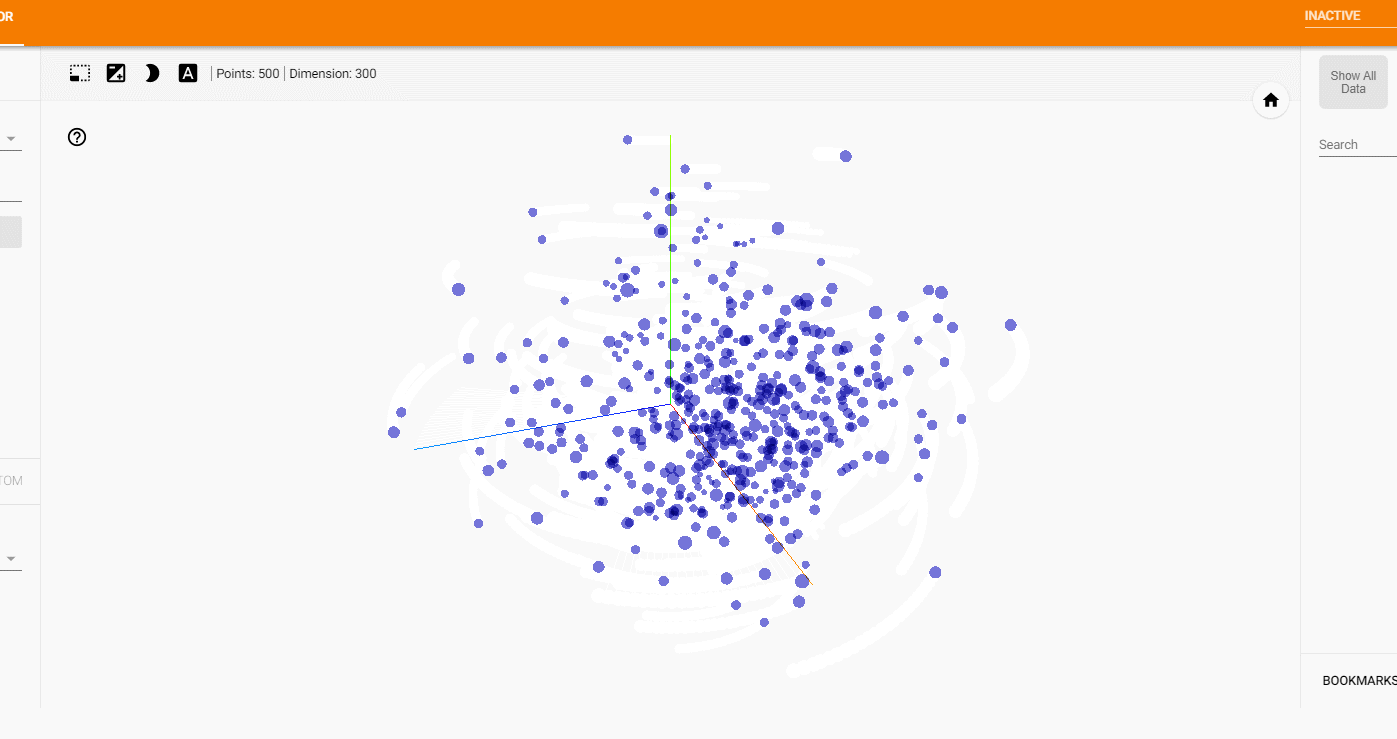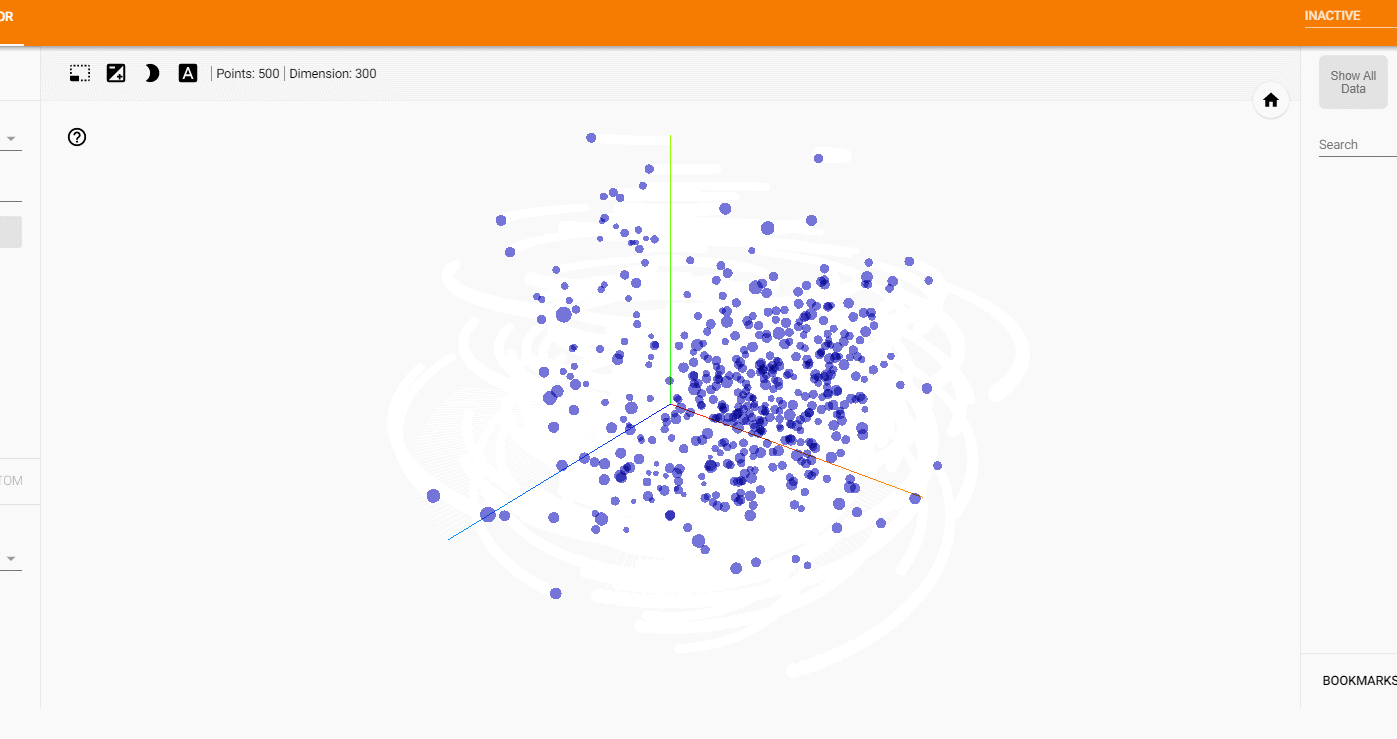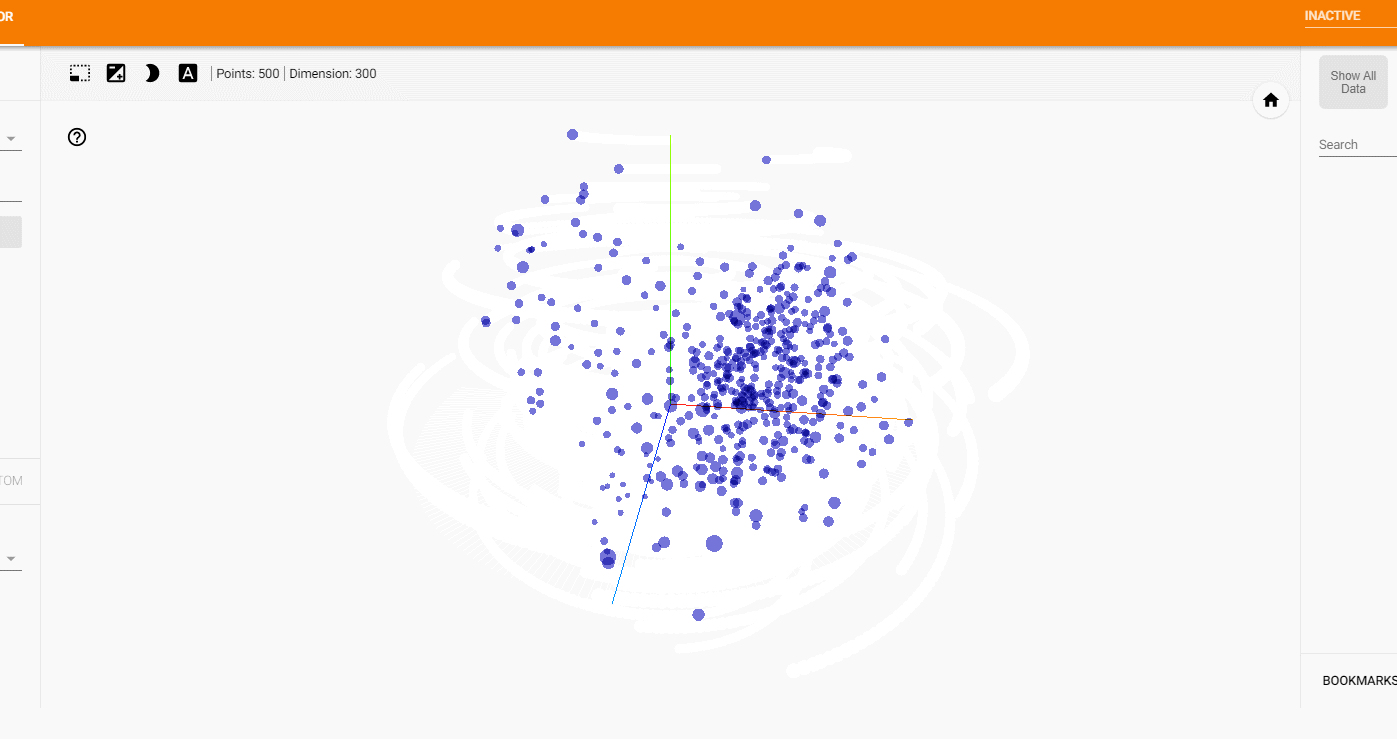
わりとバランス良くそれぞれのタイトルが可視化されました。
特定の本で見てみると、

少しわかりづらいかもしれませんが、
ある程度似ている本どうしが配置されていそうです。
また、今回はGoogle Colab上でEmbedding projectorを表示させましたが、
ベクトル情報とラベル情報をTSV形式で出力しておけば
こちらのWebサービスへアップロードすることで確認することもできます。
まとめ
以上、簡単ではありましたが、内容情報から似た本どうしの距離を可視化してみました。
ただ単にデータの一覧を眺めるだけではなく、
3Dで可視化することによってより感覚的に似た本を認識できるようになったかと思います。
ただ、中には何故この本とこの本が近いんだろうか・・・ということも多く、
精度についてはまだまだ改善する必要がありそうです。
日々精進したいと思います!